Machine Learning Framework
Python Framework that are used to create machine learning model.




Steps in Data Modelling:
Problem Definition: "What problem are we trying to solve?"
- Supervised.
- Unsupervised.
- Classification.
- Regression.
Data: "What data do we have?"
- Structured.
- Unstructured.
Evalution: "What defines succes for us?"
Features: "What do we already know about the data?"
Modelling: "Based on our problem and data, what model should we use?"
Experimentation: "How could we improve?/what else can we try?"
1. Types of Machine Learning problems
Supervised Learning:
It is called Supervise Learning, because here we have data and labels. Here a machine learning algorithms tries to use the data to predict a label.
If it guesses the label wrong, the algorithms corrects itself and tries again. This active correction why is called Supervise
Main type of Supervised Learning problems:
Classification:
- "Is this example one thing or another?"
- Binary classification = two options
- Multi-class classification = more than two options
Regression:
- "How much will this house sell for?"
- "How many people will buy this app?"
4 Features in Data : What do we already know about the data?
Use Feature variable (weight, heart rate) to predict Target variable (Heart disease?)
Numerical Feature : A number like body weigth
Categorial features : Like one in two (yes / no)
Derived feature : Look at the data and create new feature using the existing one.
Feature Engineering: Looking at different features of data and creating new ones/altering existing ones.
Feature Coverage: How many samples have different features? Ideally, every sample has the same features.
What are features of your problems?
The most important concept in machine learning.
(The training, validation and test sets or $\boxed{3 sets}$)
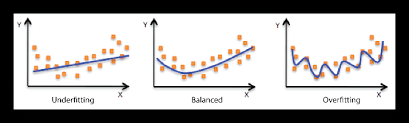
Overfitting and Underfitting Definitions
All experiments should be conducted on different portions of your data.
Training data set — Use this set for model training, 70–80% of your data is the standard.
Validation/development data set — Use this set for model hyperparameter tuning and experimentation evaluation, 10–15% of your data is the standard.
Test data set — Use this set for model testing and comparison, 10–15% of your data is the standard.
These amounts can fluctuate slightly, depending on your problem and the data you have.
Poor performance on training data means the model hasn’t learned properly and is underfitting. Try a different model, improve the existing one through hyperparameter or collect more data.
Great performance on the training data but poor performance on test data means your model doesn’t generalize well. Your model may be overfitting the training data. Try using a simpler model or making sure your the test data is of the same style your model is training on.
Another form of overfitting can come in the form of better performance on test data than training data. This may mean your testing data is leaking into your training data (incorrect data splits) or you've spent too much time optimizing your model for the test set data. Ensure your training and test datasets are kept separate at all times and avoid optimizing a models performance on the test set (use the training and validation sets for model improvement).
Poor performance once deployed (in the real world) means there’s a difference in what you trained and tested your model on and what is actually happening. Ensure the data you're using during experimentation matches up with the data you're using in production.
Fullscreen